SQL 101 - Personal Notes
Table of Contents
- SQL Basics
- Tables
- Constraints
- CRUD Operations
- Query Structuring
- Functions
- Subqueries
- Normalization
- Joins
- Indexes
SQL Basics
SQL = Structured Query Language. Programming language to manage relational databases. Does creating, updating, reading, and deleting records.
Schema
A database schema describes how data is organized. Includes data types, table names, field names, constraints, and relationships between entities.
Relational Database
Stores data so it can be easily related to other data. Example: an employee can have many projects. There's a relationship between employee and their projects.
In a relational database:
- Data is stored in "tables"
- Each table has "columns" or "fields"
- Each row is called a "record"
- Each record has a unique
idcalled the primary key
SQL Language Types
DDL (Data Definition Language)
- CREATE, DROP, ALTER, RENAME, TRUNCATE, COMMENT
DML (Data Manipulation Language)
- INSERT, UPDATE, DELETE, LOCK, CALL, EXPLAIN PLAN
DCL (Data Control Language)
- GRANT, REVOKE
DQL (Data Query Language)
- SELECT, FROM, WHERE, GROUP BY, ORDER BY, HAVING, DISTINCT, LIMIT, JOIN, UNION
TCL (Transaction Control Language)
- BEGIN TRANSACTION, COMMIT, ROLLBACK, SAVEPOINT
Databases that use SQL
MySQL, PostgreSQL, SQLite, Oracle
Basic SELECT Statement
-- Select single column
SELECT id FROM employees;
-- Select multiple columns
SELECT id, name FROM employees;
-- Select all columns (* = wildcard)
SELECT * FROM employees;
-- Select with condition
SELECT name FROM employees WHERE age > 26;
Tables
Database Operations
-- Show all databases
SHOW DATABASES;
-- Create database
CREATE DATABASE company_db;
-- Delete database
DROP DATABASE company_db;
-- Use specific database
USE company_db;
Creating Tables
CREATE TABLE employees (
id INT,
name VARCHAR(50),
age INT,
is_manager BOOLEAN,
salary DECIMAL(10,2)
);
Modifying Tables
-- Rename table
ALTER TABLE people RENAME TO users;
-- Rename column
ALTER TABLE users RENAME COLUMN tag TO username;
-- Add column
ALTER TABLE users ADD COLUMN last_name VARCHAR(50);
-- Drop column
ALTER TABLE employees DROP COLUMN is_manager;
-- Modify column
ALTER TABLE users MODIFY COLUMN last_name VARCHAR(50) NOT NULL;
-- Add foreign key
ALTER TABLE employees
ADD FOREIGN KEY (department_id) REFERENCES departments(id);
Database Migrations
What is a migration? A change to the structure of a relational database. Think of it like a Git commit, but for your database schema. Records how your data structure evolves over time.
Key Points:
- When you use ALTER TABLE to add a new column, you're performing a migration
- Essential for adapting database to changing requirements
- Fixes mistakes and rolls out new features
- In teams, ensures everyone applies the same changes in the same order
Best Practices:
- Keep migrations small and incremental
- Make them reversible
- Be careful with large databases where changes can be risky
- Don't break systems that depend on the old schema
Migration System:
- Up migration: Applies changes to move schema forward
- Down migration: Rolls changes back to previous state
- Allows safe movement between schema versions
Example Up Migration:
-- Add columns to employees table
ALTER TABLE employees ADD COLUMN was_successful BOOLEAN;
ALTER TABLE employees ADD COLUMN transaction_type TEXT;
Example Down Migration:
-- Remove columns from employees table
ALTER TABLE employees DROP COLUMN was_successful;
ALTER TABLE employees DROP COLUMN transaction_type;
Constraints
What is a Constraint? A rule created on a database that enforces specific behavior. Example: NOT NULL constraint ensures a column won't accept NULL values. If you try to insert invalid data, the insert will fail with an error.
Common Constraint Types:
- PRIMARY KEY - Uniquely identifies each row in the table
- UNIQUE - Ensures no two rows can have the same value in that column
- NOT NULL - Ensures the column cannot have NULL values
- DEFAULT - Sets a default value if none provided
- FOREIGN KEY - Links to another table's primary key
Example with All Constraints
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
hire_date DATE DEFAULT (CURRENT_DATE()),
email VARCHAR(100) UNIQUE,
phone_number VARCHAR(15) UNIQUE,
salary DECIMAL(10,2),
employment_status ENUM('active', 'on leave', 'terminated') DEFAULT 'active',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- Insert example
INSERT INTO employees (
name,
hire_date,
email,
phone_number,
employment_status
) VALUES (
'John Doe',
'2025-01-01',
'john.doe@company.com',
'+1234567890',
'active'
);
Primary Keys
A primary key consists of one or more columns that uniquely identify rows in a table.
Foreign Keys
A foreign key is a column that links to the primary key of another table.
There can be only one primary key per table, but a table can have multiple foreign keys
CREATE TABLE departments (
id INT NOT NULL,
department_name VARCHAR(50) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE employees (
id INT NOT NULL,
name VARCHAR(50) NOT NULL,
department_id INT,
PRIMARY KEY (id),
CONSTRAINT fk_departments FOREIGN KEY (department_id)
REFERENCES departments(id)
);
CRUD Operations
CRUD = Create, Read, Update, Delete (just like HTTP: POST, GET, PUT, DELETE)
Create (INSERT)
-- Insert single row
INSERT INTO employees (id, name, department, salary)
VALUES (1, 'John Doe', 'Engineering', 75000);
-- If you don't know salary, use NULL
INSERT INTO employees (id, name, department, salary)
VALUES (2, 'Jane Smith', 'Marketing', NULL);
-- Insert multiple rows (separate statements)
INSERT INTO employees (id, name, department, salary) VALUES (3, 'Bob Johnson', 'Sales', 60000);
INSERT INTO employees (id, name, department, salary) VALUES (4, 'Alice Brown', 'HR', 55000);
INSERT INTO employees (id, name, department, salary) VALUES (5, 'Charlie Wilson', 'Engineering', 80000);
-- Insert multiple rows (single statement - better)
INSERT INTO employees (id, name, department, salary)
VALUES (6, 'David Lee', 'Engineering', 70000),
(7, 'Emma Davis', 'Marketing', 65000),
(8, 'Frank Miller', 'Sales', 58000);
Auto Increment Note:
Only one column per table can be AUTO_INCREMENT, and it must be the primary key (or part of it).
Read (SELECT)
SELECT * FROM employees;
How CRUD connects to web apps:
- Front-end processes user input (form submission)
- Front-end sends data to server via HTTP request (POST)
- Server makes SQL query to database (INSERT statement)
- Server responds with status code (hopefully 200 success!)
Update
UPDATE employees
SET name = 'John Smith'
WHERE id = 1;
-- Update multiple columns
UPDATE employees
SET salary = 85000, department = 'Senior Engineering'
WHERE id = 1;
Delete
DELETE FROM employees
WHERE id = 2;
Truncate vs Drop
-- Truncate: removes all rows but keeps table structure
TRUNCATE TABLE employees;
-- Drop: removes table and all data completely
DROP TABLE employees;
Query Structuring
Basic Query Functions
COUNT:
SELECT COUNT(*) FROM employees;
WHERE:
SELECT name FROM employees WHERE salary >= 50000;
IS NULL / IS NOT NULL:
SELECT name FROM employees WHERE manager_id IS NULL;
SELECT name FROM employees WHERE manager_id IS NOT NULL;
AS (Aliases):
SELECT id AS employee_id, name AS employee_name
FROM employees;
BETWEEN:
SELECT name, salary
FROM employees
WHERE salary BETWEEN 30000 AND 60000;
DISTINCT:
SELECT DISTINCT department
FROM employees;
Logical Operators
=Equal!=,<>Not equal>Greater than>=Greater than or equal to<Less than<=Less than or equal toIS NULLA null valueIS NOT NULLA non-null valueINMatches a value in a listNOT INDoesn't match a value in a listBETWEENWithin a rangeNOT BETWEENNot within a rangeLIKEMatches a patternNOT LIKEDoes not match a pattern
AND / OR
-- AND: both conditions must be true
SELECT name, salary, department
FROM employees
WHERE department = 'Engineering'
AND salary BETWEEN 70000 AND 90000;
-- OR: either condition can be true
SELECT name, salary, department
FROM employees
WHERE department = 'Engineering'
OR salary > 80000;
IN
-- Simple way to use instead of multiple OR conditions
SELECT name, department
FROM employees
WHERE department IN ('Engineering', 'Marketing', 'Sales');
-- With subquery
SELECT name FROM employees
WHERE department_id IN (
SELECT id FROM departments
WHERE location = 'New York'
);
LIKE (Pattern Matching)
The LIKE keyword uses % and _ wildcard operators.
% operator matches zero or more characters:
-- Names starting with 'John'
SELECT * FROM employees WHERE name LIKE 'John%';
-- Names ending with 'son'
SELECT * FROM employees WHERE name LIKE '%son';
-- Names containing 'ann'
SELECT * FROM employees WHERE name LIKE '%ann%';
_ operator matches exactly one character:
-- Names like 'Jon', 'Jan', 'Jim' (3 letters starting with J)
SELECT * FROM employees WHERE name LIKE 'J_n';
-- Names like 'Smith', 'Smyth' (5 letters starting with 'Sm')
SELECT * FROM employees WHERE name LIKE 'Sm__h';
LIMIT
SELECT * FROM employees
WHERE department = 'Engineering'
LIMIT 10;
ORDER BY
-- Ascending order (default)
SELECT name, salary FROM employees
ORDER BY salary;
-- Descending order
SELECT name, salary FROM employees
ORDER BY salary DESC;
-- Multiple columns
SELECT name, department, salary FROM employees
ORDER BY department, salary DESC;
Functions
A function is a set of saved SQL statements that performs some task and returns a value.
Aggregate Functions
COUNT:
SELECT COUNT(*) FROM employees;
MAX:
SELECT MAX(salary) FROM employees;
MIN:
SELECT name, MIN(salary) FROM employees;
SUM:
SELECT SUM(salary) FROM employees;
AVG:
SELECT AVG(salary) FROM employees;
GROUP BY
SELECT department, COUNT(id)
FROM employees
GROUP BY department;
SELECT department, SUM(salary)
FROM employees
GROUP BY department;
SUBSTRING
SELECT SUBSTRING('hello world', 1, 5); -- 'hello'
-- This is like Python slicing
HAVING
The HAVING clause is similar to WHERE, but it operates on groups after they've been grouped, rather than rows before they've been grouped.
SELECT department, COUNT(id) AS count
FROM employees
GROUP BY department
HAVING count > 5;
The difference:
WHEREcondition is applied to all data in a query before it's grouped byGROUP BYHAVINGcondition is only applied to the grouped rows that are returned after aGROUP BYis applied
This means: if you want to filter based on the result of an aggregation, use HAVING. If you want to filter on a value in the raw data, use WHERE.
ROUND
SELECT name, ROUND(AVG(salary), 2)
FROM employees
GROUP BY name;
Subqueries
Subquery = a query inside another query. MySQL runs the inner query first, then uses that result in the outer query.
-- Find employees in New York departments
SELECT id, name, department_id
FROM employees
WHERE department_id IN (
SELECT id
FROM departments
WHERE location = 'New York'
);
-- Find employees in Engineering department
SELECT name
FROM employees
WHERE department_id = (
SELECT id
FROM departments
WHERE department_name = 'Engineering'
);
Normalization
Table Relationships
3 types of relationships:
- One-to-one
- One-to-many
- Many-to-many
One-to-One
One record relates to exactly one other record. Example: an employee has exactly one employee_id. Or one email_preference per employee.
One-to-Many
Most common relationship. One record in table A relates to many records in table B. But records in table B can only relate to one record in table A.
Examples:
- One
departmenthas manyemployees - One
employeeworks on manyprojects
CREATE TABLE departments (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL
);
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
department_id INT,
CONSTRAINT fk_departments
FOREIGN KEY (department_id)
REFERENCES departments(id)
);
Many-to-Many
Multiple records in table A can relate to multiple records in table B.
Examples:
employeesandprojects- employees work on many projects, projects have many employeesemployeesandskills- employees have many skills, skills belong to many employees
Joining Table
To handle many-to-many, create a joining table with both primary keys.
CREATE TABLE employee_projects (
employee_id INT,
project_id INT,
UNIQUE(employee_id, project_id)
);
This prevents duplicate combinations but allows multiple rows with same employee_id OR same project_id.
Database Normalization
Method for structuring your database schema to:
- Improve data integrity
- Reduce data redundancy
Data Integrity = accuracy and consistency of data. Example: storing employee's age vs birth_date. Age becomes wrong over time, but birth_date stays correct. Better to store birth_date and calculate age when needed.
Data Redundancy = same data stored in multiple places. Problem: when you change data in one place, other copies become inconsistent.
Normal Forms: 1st (least normalized) → Boyce-Codd (most normalized) More normalized = better data integrity + less duplicate data.
Primary Key in Normalization: In normalization context, "primary key" means the collection of columns that uniquely identify a row. Can be single column or multiple columns (composite key).
Example: employee_projects table's primary key is combination of employee_id + project_id:
CREATE TABLE employee_projects (
employee_id INT,
project_id INT,
UNIQUE(employee_id, project_id)
);
1st Normal Form (1NF)
2 simple rules:
- Must have a unique primary key
- A cell can't have a nested table as its value
BAD (NOT 1NF):
| name | age | |
|---|---|---|
| John | 27 | john@company.com |
| John | 27 | john@company.com |
| Jane | 25 | jane@company.com |
Problem: duplicate rows = no unique primary key
GOOD (1NF):
| id | name | age | |
|---|---|---|---|
| 1 | John | 27 | john@company.com |
| 2 | John | 27 | john@company.com |
| 3 | Jane | 25 | jane@company.com |
Fix: add unique id column
Note: You should almost never design a table that doesn't follow 1NF. It's just a good idea.
2nd Normal Form (2NF)
Follows 1NF rules + one more rule for composite primary keys:
- All non-primary-key columns must depend on the entire primary key, not just part of it
BAD (NOT 2NF):
Primary key = first_name + last_name
| first_name | last_name | first_initial |
|---|---|---|
| John | Doe | J |
| Jane | Smith | J |
Problem: first_initial only depends on first_name, not the full primary key = redundant
GOOD (2NF): Split into two tables:
Table 1:
| first_name | last_name |
|---|---|
| John | Doe |
| Jane | Smith |
Table 2:
| first_name | first_initial |
|---|---|
| John | J |
| Jane | J |
Rule of thumb: Optimize for data integrity first. If you have speed issues, de-normalize later.
3rd Normal Form (3NF)
Follows 2NF rules + one more rule:
- All non-primary-key columns must depend only on the primary key (not on other non-primary-key columns)
BAD (NOT 3NF):
Primary key = id
| id | name | first_initial | |
|---|---|---|---|
| 1 | John Doe | J | john@company.com |
| 2 | Jane Smith | J | jane@company.com |
Problem: first_initial depends on name column, not the primary key = violates 3NF
GOOD (3NF): Split into two tables:
Table 1:
| id | name | |
|---|---|---|
| 1 | John Doe | john@company.com |
| 2 | Jane Smith | jane@company.com |
Table 2:
| name | first_initial |
|---|---|
| John Doe | J |
| Jane Smith | J |
Rule of thumb: Same as 2NF - optimize for data integrity first, de-normalize for speed later.
Boyce-Codd Normal Form (BCNF)
Follows 3NF rules + one more rule:
- A column that's part of a primary key can't depend on a column that's NOT part of that primary key
Only comes up when there are multiple possible primary key combinations that overlap ("overlapping candidate keys").
Rare to see BCNF-specific issues in practice.
Rule of thumb: Same as others - optimize for data integrity first, de-normalize for speed later.
Normalization Review
Honestly, the exact definitions of 1st, 2nd, 3rd and BCNF normal forms aren't that important in day-to-day work.
What IS important: understand the basic principles of data integrity and data redundancy.
Rules of Thumb for Database Design:
- Every table should have a unique identifier (primary key)
- 90% of the time, that's a single column named
id - Avoid duplicate data
- Avoid storing data that depends on other data. Compute it when needed instead.
- Keep schema simple. Optimize for normalized database first. Only denormalize for speed when you hit performance problems.
Joins
Joins let us use the relationships between tables. Query multiple tables at the same time.
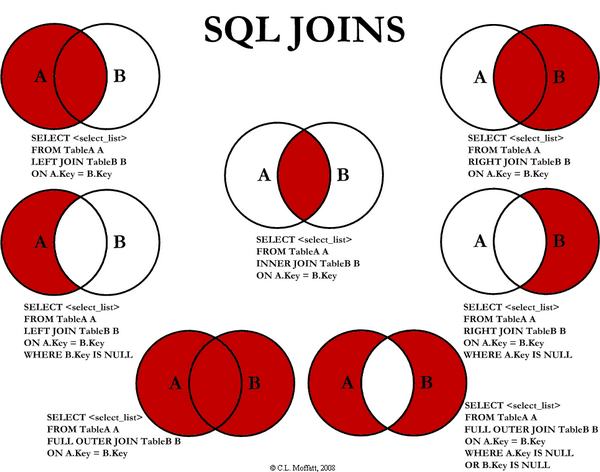
INNER JOIN
Most common join. Returns records from table_a that have matching records in table_b.
Use ON clause to tell database how to "match up" rows from each table.
When same column name exists in both tables, specify which table using table_name.column_name.
SELECT *
FROM employees
INNER JOIN departments
ON employees.department_id = departments.id;
This query:
employees.department_id= department_id column from employees tabledepartments.id= id column from departments table
Returns all fields from both tables.
Table Aliases
-- Use aliases to make queries shorter
SELECT e.name, d.name
FROM employees e
INNER JOIN departments d
ON e.department_id = d.id;
LEFT JOIN
Returns every record from table_a (left table) regardless of matches + any matching records from table_b.
SELECT e.name, d.name
FROM employees e
LEFT JOIN departments d
ON e.department_id = d.id;
RIGHT JOIN
Returns all records from table_b (right table) regardless of matches + any matching records from table_a.
FULL JOIN
Combines LEFT JOIN and RIGHT JOIN. Returns all records from both tables regardless of matches.
Multiple Joins
Join more than 2 tables:
SELECT *
FROM employees
LEFT JOIN departments
ON employees.department_id = departments.id
INNER JOIN locations
ON departments.location_id = locations.id;
Indexes
Index = in-memory structure that makes queries run fast. Most indexes are binary trees or B-trees stored in RAM/disk. Makes it easy to look up the location of an entire row.
PRIMARY KEY columns are indexed by default = you can look up a row by its id very quickly.
For other columns you want to do quick lookups on, you need to index them.
Indexing creates a new b-tree structure where values are sorted to keep lookups fast. Big-O complexity: O(log(n)).
CREATE INDEX
CREATE INDEX salary_idx ON employees (salary);
Common naming: column_name_idx
Why Not Index Everything?
Don't overengineer. If you index every column = hundreds of b-trees in memory = bloated memory.
Each time you insert a record, it needs to be added to many trees = slower insert speed.
Rule of thumb:
Add indexes to columns you do frequent lookups on. Leave everything else un-indexed. You can always add indexes later.
Multi-Column Indexes
Speed up lookups that depend on multiple columns.
CREATE INDEX name_department_idx
ON employees (name, department);
Multi-column index is sorted by first column first, second column next, etc.
Lookup on only the first column gets almost all performance improvements. Lookups on only second/third column have very degraded performance.
Rule of Thumb: Only add multi-column indexes if you're doing frequent lookups on a specific combination of columns.